Respect the Neural Network of Your Business


Earlier this year I shared a tale of woe. One of my long-term clients had suffered a ransomware attack due mostly to the negligence of the business leadership to be respectful of the need to maintain their information technology infrastructure and be vigilant against external threats from bad actors (along with internal threats from system degradation).
Although the situation was eventually resolved and the business was able to recover their data and continue on their way, it caused considerable disruption to its operations and they incurred substantial expense such as; the rushed modernizing of their information systems, hiring consultants, engaging a firm to negotiate the ransom with the bad-guys, and paying the negotiated ransom. It was an anxious and painful experience.
A few months later, and I find myself at another client. In this case, I was hired to help turn around the business. This company was entirely broken and there was not a single business function that was operating at an acceptable level, including Information Technology (IT).
Ignoring the IT network and infrastructure
The first sign of trouble with their information systems and the level of respect (or lack thereof) that was given it was when I tried to save a document to a workstation in their conference room and the drive’s free space was showing “red”. It had less than 5% available space on the hard drive. Although I reported the situation to their IT Department, there was a lack of concern in their response. Was there anything of importance on it? Nobody knew. Was the drive ever backed-up? No. If the drive failed, would anyone care? Evidently not.
Like my client who was the victim of ransomware, their IT infrastructure was neglected and hopelessly outdated. I use the work “hopelessly” because most of the workstations were beyond their useful life and could not be reasonably updated. Even the server itself was over a decade old and sorely in need of being replaced.
So, imagine my alarm when I tried to save something to the server and saw that the free space on many of the drives were also in the “red”. Knowing that an ERP system that runs out of space (especially during a posting process) would result in folks having a bad day, I alerted the IT Department again.
They let me know that the ERP system was on a different drive than the ones in red and it had “adequate” space so that I shouldn’t worry; and that the drive I was concerned about was only for documents (like that makes it better?). Still, this is not an acceptable situation. What do you think? Do you see any cause for alarm?
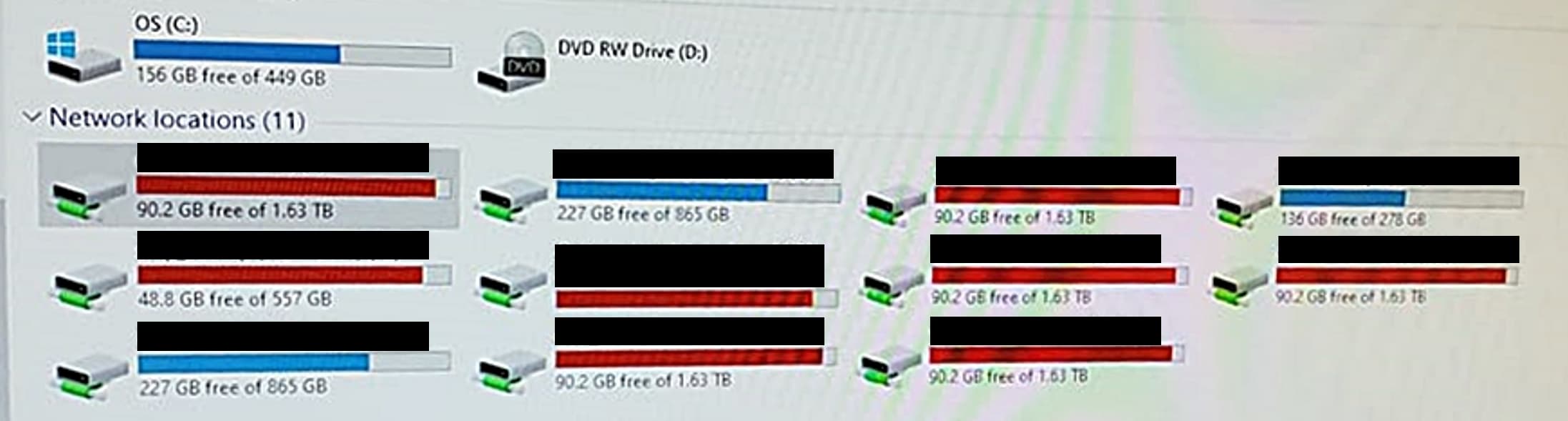
They also assured me that the server was being backed up. Normally, their sharing this would satisfy me. But that they didn’t routinely test the backup was of great concern. My client who was a victim of ransomware also had a backup. But it wasn’t tested. And when a backup was needed, the only valid backup to be found was several months old and not much use. On top of this, the company’s backups and the server were in the same building.
Pro Tip: If your backups and the data you are backing up are in the same place, you have no backup.
The client, rightfully so given the age of the infrastructure, was considering the replacement of the servers and updating the various devices and applications in support of the server such as; data backup systems, uninterruptable power supplies, switches, and so on. The capital investment for this approached $200,000; a considerable amount of money for a company in a turn-around situation.
The question was; could they find the money and is it best used right here and right now?

Being Reckless
One day, all of the devices on the network became disconnected and couldn’t find the server. While the browser applications installed could still see the server and function, every other application that was client-server based could not see the server; including just wanting to look at the drives.
Investigation found that their IT technician, the person responsible for maintaining the network and all its devices, wanted to take a census of their IT infrastructure. So, he downloaded an application he found on the internet that would take a census of the network and proceeded to run it. When he did, the application instead deleted each device’s registration in the Active Directory, which disconnected and eliminated all the devices from the network.
In consultation with my technical experts when the problem was discovered and became known to me, they shared with me that the backup system, theoretically, should have backed-up the Active Directory in addition to everything else on the network server. But the company’s IT technician didn’t think of that. Why? I don’t know. And when I suggested it to the IT Department, they didn’t seem to either understand what I was telling them or didn’t care to try. Instead, they proceeded to manually reconnect all 150(ish) devices on the network, which cost most of those using the system a day of effort.
Pro Tip: Don’t just install random software without vetting and testing.
Managed Service Provider? Yes or No?
The company’s IT department consisted of two full-time employees (an IT technician and programmer) and one part-time contract programmer.
Given the multitude of IT challenges, they were considering engaging a Managed Service Provider (MSP) which Gartner defines as; a company that “delivers services, such as network, application, infrastructure and security, via ongoing and regular support and active administration on customers’ premises, in their MSP’s data center (hosting), or in a third-party data center.
MSPs may deliver their own native services in conjunction with other providers’ services (for example, a security MSP providing sys admin on top of a third-party cloud IaaS). Pure-play MSPs focus on one vendor or technology, usually their own core offerings. Many MSPs include services from other types of providers. The term MSP traditionally was applied to infrastructure or device-centric types of services but has expanded to include any continuous, regular management, maintenance and support.”
The proposal they received from one MSP required an investment of approximately $6,500 for setup and a monthly commitment of approximately $11,500. For this, they received services such as; support and help desk, security solutions and services, infrastructure monitoring, being a liaison with other technology vendors that might be involved with the company, quarterly strategy meetings and a technology roadmap. Other services were charged in addition.
Again, since they were in a turn-around situation, was this the best use of the scant resources available right here and right now?
What they were not considering was a reconfiguration of the IT Department itself. For instance, why does a manufacturing company with 150 employees need two programmers? The company was not special and requiring such a level of development. Why were they not buying more “off the shelf” solutions? Or subcontracting development costs to more economical sources? And what if the role of the IT technician was expanded (even if the existing IT technician had to be replaced if not capable) to include network management, security, backups, and so forth; roles they should already be performing with the help of specialized software (vetted and tested, of course)?
Pro Tip: If you are a small business, you need to watch the spend for value received in IT. Certainly, protect your assets and infrastructure. But you are not special, so don’t act as if you are. It’s a waste.
How not to do agile development
As most people who read my articles will know, I am a big fan of the Observe, Orient, Decide, Act (OODA) loop which was first conceived by USAF Colonel John Boyd in the 1950’s as an approach to improve the success of fighter pilots by training them to make quick and iterative decisions towards a desired outcome.
As such, I am also a big fan of its more contemporary incarnation, Agile. And not just for software development, which was Agile’s origin, but for the pursuit and deployment of almost any strategy.
You can read more of my thoughts comparing and contrasting OODA and Agile in my article entitled; “OODA and Agility; Reaching a Conclusion Faster”.
But there is a right way and a wrong way in using an Agile approach to develop applications; and this company was doing it in the most wrong way possible.
Anyone who uses social media or Software as a Service (SaaS) applications will have experienced this. We log into the application and something that we consistently used was changed, moved, or removed; or there are new functions and features that were introduced of which we are unaware.
If we are lucky, there might have been some email or message sent to us alerting us to the changes pending in advance of their being introduced. But we will read it only accidentally because it’s hidden in and among all the other marketing communications from the creators of the application which we routinely ignore. I mean, who has the time?
When we notice the change, we might be able to find a document in the online help services that explains what the changes are. Better yet might be a video tutorial on its use (changed or new). If the functionality has been removed or modified in a manner which eliminates our using it as we had, well, that is usually just too bad for us, and we will have to live without.
The approach at this company was worse, far worse.
As I previously mentioned, the company had one full-time programmer on staff and one contract programmer. It escapes me why a company that is a discreet manufacturer producing items that were not particularly unique or special at all believed they were unusual enough to require all that programming firepower on staff. But still, there we were.
The owner would routinely see something in the systems that he thought should be changed and tell the programmers. Some of the changes were small (screens and reports) and some of them were substantial (warehouse and material tracking system). The list of projects was always growing; mostly because of the continuous reprioritization of projects by the owner. This reprioritization also resulted in the list of projects that were partially completed also growing (with some projects on the trajectory for not ever being completed, although time was spent on them).
There were never any specifications developed; rarely even a “back of the napkin” diagram. Most of the development guidance was in the form of ad-hoc verbal communication between the company owner and the programmers (usually starting with a “Hey, ya’ got a minute?”). And while there was the necessary on-going collaboration between the owner and the programmers, the users were rarely (if ever) engaged to gain their thoughts about what was needed, whether it was needed, and how it should work.
Pro Tip: Just because its obvious to you doesn’t mean its obvious to everyone else. Be patient and take the time to ensure the intended results are understood by the people who are expected to deliver and use the results.
There was also minimal testing (never under load) before rolling out the new code. There was never any documentation detailing what was done, why it was done, and how to use it. And there was never any formal announcement to the users that the code and been cut, introduced, and ready for use.
Pro Tip; Remember to manage your risk profiles. With no catalog of what programs and modifications were created and no documentation of what they did and how they did it, I hope the programmers stays with the company and remains in good health forever.
I found it rather funny and sad that oftentimes users would share a need with the owner and the owner would inform the user that it existed and show them. Or that users were using the old versions of the application because they didn’t know that there was a new one or how to access it.
But it was the project selection process that bothered me the most. Why were all these projects on the board in the first place? This company was not special in any way.
It was because the owner would perceive an opportunity for improvement, get all excited about it thinking it was most critical, and bump everything else in the project queue; just not thinking it all the way through before acting. Further, there was never an impact evaluation. Spending a buck to save a nickel was okay because it was never questioned.
Pro Tip: Franky says, “Relax, don’t do it”. Or at least don’t be impulsive. But do be collaborative, engage the users, and engineer the design and roll-out processes.
Don’t create the chaos
One of the reasons the company was in turn-around is that their production processes (and all other processes) were in desperate need of stabilization. Once stabilized, the processes could then be standardized and optimized. But instead of being a stabilizing force, the owner caused chaos.
And not only did he cause the chaos, but he also refused to stop causing chaos when others brought it to his attention. He didn’t think through the impact of his actions, and he never consulted with those at the pointy end of the stick who were going to have to endure the results.
This was especially obvious when it came to the company’s information systems; the neural network of the business. With the systems changing every day without properly communicating the changes, people were constantly being confused and frustrated to the point of becoming ambivalent.
Pro Tip: People can’t follow if they don’t know where they are going or how to get there.
Rate of digestion.
Turning around a company is like coming on the scene of an accident with victims. First you assess the situation and make sure the area is safe and secure. Then you engage the victims and triage them for the severity of their wounds. Then you treat the victims who are in most critical need of care first to the point they are stable. Repeat with the subsequent victims until all are ready for transport where the real treatments can be provided and they can start the healing process.
The owner of this company lacked discipline to assess, prioritize, engage in a meaningful manner, verify that the actions planned actions were going to be successful, roll out the changes in a deliberate manner, and then verify the changes were working as expected.
He did not Plan, Do, Check, and Act.
He was trying to eat the elephant in one bite instead of one bite at a time; and it was his company that was choking on it.
About the author

Joseph Paris is an international expert in the field of Operational Excellence, organizational design, strategy development and deployment, and helping companies become high-performance organizations. His vehicles for change include being the Founder of; the XONITEK Group of Companies; the Operational Excellence Society; and the Readiness Institute.
He is a sought-after speaker and lecturer and his book, “State of Readiness” has been endorsed by senior leaders at some of the most respected companies in the world.
Click here to learn more about Joseph Paris or connect with him on LinkedIn.